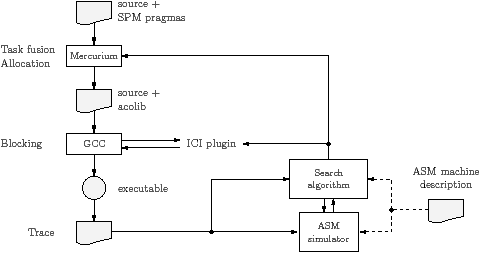
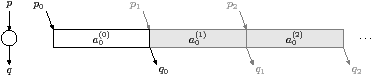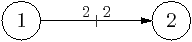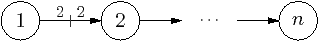The first part of this thesis is concerned with the stream compiler. The stream compiler builds an executable that runs efficiently on the target machine, applying, amongst others, the transformations explained in Chapter 3. These transformations require the target to be characterised using some kind of model. This chapter describes the Abstract Streaming Machine (ASM), the machine description and performance model developed as part of the ACOTES project [M+11]. The ACOTES project developed the framework for a stream compiler illustrated in Figure 2.1, and discussed in Section 1.3.
There are two parts to the ASM. The ASM machine description describes the system architecture of the target as a graph, and is sufficient for the partitioning algorithm, which balances loads on the processors and interconnects. Other transformations, such as queue sizing, need to see the system’s dynamic behaviour. When the program’s behaviour is simple and regular, an analytical model of its progress may suffice. For example, the critical cycle algorithm discussed in Section 3.14 assumes that the program repeats exactly the same operations, with the same execution times and communication latencies over and over, and represents the whole program’s execution using a cyclic directed graph. When the program’s behaviour is irregular, there is no alternative to simulation or real execution.
The ASM simulator is a coarse-grain simulator, which models the execution of a mapped stream program on the target, producing statistics and a Paraver trace. The simulator can itself be driven by a trace, obtained from a real execution, which allows it to follow conditions and model varying computation times. The ASM simulator needs an execution model for the program, and this is given by the ASM program model. The trace format and program model have been designed to allow a single trace to be reused for several different mappings.
The ASM supports homogeneous and heterogeneous targets; that is, the processors’ instruction sets and microarchitectures may or may not be all the same. A homogeneous multiprocessor, comprised of identical cores, is easier to design, and easier to program. A heterogeneous target, in contrast, may have lower power consumption because different cores can be tuned for different functions [CCG+00], and it mitigates Amdahl’s law [Amd67, KTJR05], since work that cannot be done in parallel can be done by a more powerful, but less frugal, processor.
The ASM also supports both shared and distributed memory. Shared memory is required by many multithreaded C programs, so is common for machines with about 32 or fewer cores, but it is expensive to scale cache-coherent shared memory to large numbers of processors.1 The cost to implement cache coherence is perhaps 5–10% of the total power consumption of the data cache accesses [ESD02] in an eight-way SMP, and the cost grows with the number of processors. Distributed memory is easier to implement in hardware, but it is harder to program because data can only be sent between cores using explicit messages such as send–receive (two-sided communication) or get–put (one-sided communication).
The ASM models shared or distributed memory only as required by the transformations in a stream compiler. If memory is shared, it does not model sharing granularity, whether the shared memory is coherent or not, and the intricacies of the consistency model [AG02]. All of the above differ significantly between implementations, but are needed only by the run-time developer. Similarly, the ASM does not tell the run-time developer how to program DMA transfers.
The ASM is also not needed for code generation, which produces object code for individual functions, which run on a single core. This problem is addressed quite adequately by existing compilers, and it would be both pointless and prohibitively expensive to try to duplicate.2
The ASM is also the execution model for the ASM simulator. ACOTES supports static scheduling, and has no support for dynamic scheduling. The ASM program model, therefore is a model for statically scheduled stream programs, which is the focus of Chapter 3.
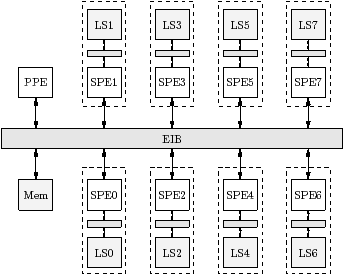
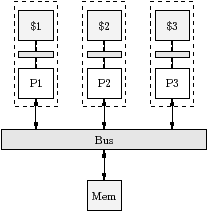
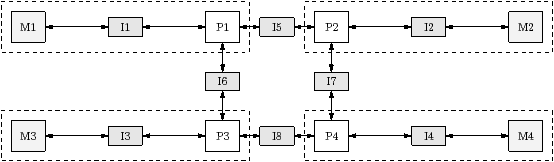
The target is represented as a undirected bipartite graph H=(V,E), where V is the set of vertices, which represent resources, and E is the set of edges, which represent interconnects. The resources are the processors and the memories. Figure 2.2 shows the topology of three example targets. The machine description defines the machine visible to software, provided by the OS and acolib, which may be different from the physical hardware. For example, Playstation 3 has a Cell B.E. (processor) [CRDI05], which has one PPE and eight SPE accelerators, but the Operating System makes just six of the SPEs available to software; furthermore, the OS does not reveal the mapping from virtual to physical processor. We also assume that the processors used by the stream program are not time-shared with other applications while the program is running.
(a) Definition of a processor
Parameter Description name Unique name in platform namespace clockRate Clock rate, in GHz hasIO True if the processor can perform IO addressSpace List of the physical memories addressable by this processor and their virtual address pushAcqCost Cost, in cycles, to acquire a producer buffer (before waiting) pushSendFixedCost Fixed cost, in cycles, to push a block (before waiting) pushSendUnit Number of bytes per push transfer unit pushSendUnitCost Incremental cost, in cycles, to push pushUnit bytes popAcqFixedCost Fixed cost, in cycles, to pop a block (before waiting) popAcqUnit Number of bytes per pop transfer unit popAcqUnitCost Incremental cost, in cycles, to pop popUnit bytes popDiscCost Cost, in cycles, to discard a consumer buffer (before waiting)
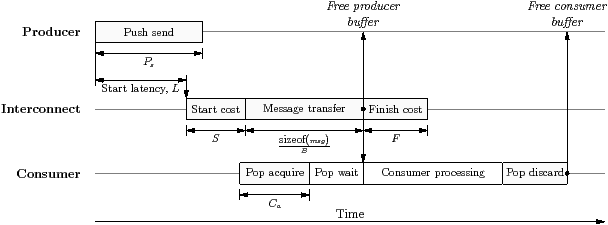
Parameter Description name Unique name in platform namespace clockRate Clock rate, in GHz elements List of the names of the elements (processors and memories) on the bus interfaceDuplex If the bus has more than one channel, then define for each processor whether it can transmit and receive simultaneously on different channels interfaceRouting Define for each processor the type of routing from this bus: storeAndForward, cutThrough, or None startLatency Start latency, L, in cycles startCost Start cost on the channel, S, in cycles bandwidthPerCh Bandwidth per channel, B in bytes per cycle finishCost Finish cost, F, in cycles numChannels Number of channels on the bus multiplexable False for a hardware FIFO that can only support one stream
(b) Definition of an interconnect
Figure 2.3: Processor and interconnect parameters of the ASM and values for two example targets (measured on Cell and estimated for a four-core SMP)
Figure 2.3 shows the parameters used to characterise each resource in the system, together with their values for the Cell B.E. with the Cell implementation of acolib, and estimated values for an SMP. Each processor core has a separate definition, allowing the ASM to support both heterogeneous and homogeneous systems.
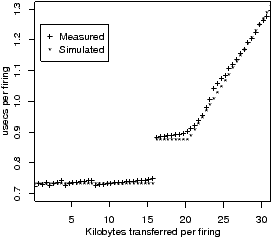
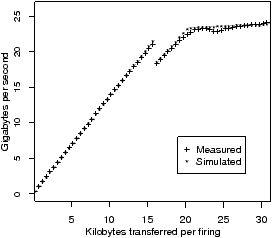
Each processor is defined using the parameters in Figure 2.3(a). As discussed above, the details of the processor’s ISA and micro-architecture are already described in the compiler’s back-end, so are not duplicated in the ASM. The ASM processor description lists the costs of the acolib calls. The costs of ProducerSend and ConsumerAcquire are given by a staircase function; i.e. a fixed cost, a block size, and an incremental cost for each complete or partial block after the first. This variable cost is necessary both for FIFOs and for distributed memory with DMA. For distributed memory, the size of a single DMA transfer is often limited by hardware, so that larger transfers require additional processor time in ProducerSend to program multiple DMA transfers. The discontinuity at 16KB in Figure 2.10, seen on the Cell B.E., is due to this effect.
The addressSpace and hasIO parameters provide constraints on the compiler mapping, but are not required to evaluate the performance of a valid mapping. The former defines the local address space of the processor; i.e. which memories are directly accessible and where they appear in local virtual memory, and is used to place stream buffers. The model assumes that the dominant bus traffic is communication via streams, so either the listed memories are private local stores, or they are shared memories accessed via a private L1 cache. In the latter case, the cache should be sufficiently effective that the cache miss traffic on the interconnect is insignificant. The hasIO parameter defines which processors can perform system IO, and is a simple way to ensure that tasks that need system IO are mapped to a capable processor.
Each interconnect is defined using the parameters shown in Figure 2.3(b). The system topology is given by the elements parameter, which for a given interconnect lists the adjacent processors and memories. Each interconnect is modelled as a bus with multiple channels, which has been shown to be a good approximation to the performance observed in practice when all processors and memories on a single link are equidistant [GLB00]. If there are more messages than channels, then messages have to wait, and are arbitrated using a first-come-first-served policy. There is a single unbounded queue per bus to hold the messages ready to be transmitted. The compiler statically allocates streams onto buses, but the choice of channel is made at runtime. The interfaceDuplex parameter defines for each resource; i.e. processor or memory, whether it can simultaneously read and write on different channels.
The bandwidth and latency of each channel is controlled using four parameters: the start latency (L), start cost (S), bandwidth (B), and finish cost (F). In transferring a message of size n bytes, the latency of the link is given by L + S + ⌊n/B⌋ and the cost incurred on the link by S + ⌊n/B⌋ + F. This model is natural for distributed memory machines, and amounts to the assumption of cache-to-cache transfers on shared memory machines. Figure 2.5 shows the temporal behaviour of a single message transfer on a bus.
Hardware routing is controlled using the interfaceRouting parameter, which defines for each processor whether it can route messages from this interconnect: each entry can take the value storeAndForward, cutThrough or None. Memory controllers and routers are modelled as a degenerate type of processor.
Each memory is defined using the parameters shown in Figure 2.4. The latency and bandwidth figures are currently unused in the model, but may be used by the compiler to refine the estimate of the run time of each task. The memory definitions are used to determine where to place communications buffers, and provide constraints on blocking factors.
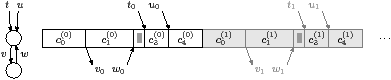
The ASM program model is the execution model of the compiled program running under the ASM simulator. The compiled stream program is a connected directed graph of tasks and point-to-point streams, as described later in Section 3.2.1. Kernels are present in the source program, whereas tasks, each of which implements one or more kernels, are present in the executable.
Tasks communicate using four acolib communications primitives, which use a push model similar to the DBI (Direct Blocking In-order) variant of TTL [vdWdKH+04]. These primitives push or pop buffers, which contain a fixed number of elements chosen by the compiler. The buffer sizes can be different at the producer and consumer ends, but the following description assumes they are the same, to avoid extraneous detail. A block is the contents of one buffer, and i and j count blocks, starting at zero. The first argument, s, is the stream. Each end of the stream has a fixed number of buffers, chosen by the compiler using the algorithm in Section 3.3, and denoted np(s) and nc(s).
(a) Task containing a single subtask a0; the superscript is the iteration number
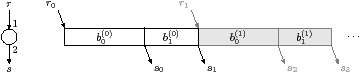
(b) Interpolation task containing subtasks b0 and b1
(c) Irregular task containing subtasks c0, c1, c2, c3 and c4
(d) Execution and communication of the program of Figure 2.7 and Figure 2.8
Figure 2.6: Building tasks from subtasks
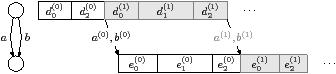
The program model uses a trace, and the same trace can be reused for several different mappings of the program onto the target—as illustrated by the small feedback loop in the bottom right of Figure 1.5. This reuse avoids recompiling the whole program via Mercurium and GCC, just to obtain a new trace. Because tasks may have complex irregular behaviour, the trace contains control flow information inside the tasks.
The basic unit of sequencing inside a task is the subtask, which pops a fixed number of elements from each input stream and pushes a fixed number of elements on each output stream. In detail, the work function for a subtask is divided into three consecutive phases. First, the acquire phase obtains the next set of full input buffers and empty output buffers, using ProducerAcquire and ConsumerAcquire. Second, the processing phase works locally on these buffers, and is modelled using a fixed processing time, determined from a Paraver [CEP] trace. Finally, the release phase discards the input buffers using ConsumerDiscard, and sends the output buffers using ProducerSend, releasing the buffers in the same order they were acquired. This three-stage model is not a deep requirement of the ASM, and was introduced as a convenience in the implementation of the simulator, since our compiler will naturally generate subtasks of this form.
A task is the concatenation of one or more subtasks. Figure 2.6(a), (b) and (c) show how to represent some tasks that perform an arbitrary fixed sequence of communication and computation. The superscript is the iteration number of the task. Although a stream has exactly one producer and one consumer task, it may be accessed from more than one subtask. For example, Figure 2.6(b) has two subtasks, b0 and b1, and they both push elements on stream s. In order to support control flow, all subtasks of all tasks are placed into a common control-flow hierarchy. Subtasks are executed conditionally or repeatedly based on a Paraver trace attached to this control-flow hierarchy, with this common trace ensuring that communicating tasks behave consistently.
Each if or while statement has an associated control variable, which gives its sequence of arguments. As part of the conversion from SPM to C, the Mercurium tool inserts calls to the trace collection functions, which record the control variables in the Paraver trace. The control variables are represented using event records in the trace; the event type identifies the control variable, and the event value gives its value.
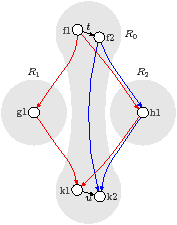
Figure 2.7(a) is the source code for an example stream program containing six kernels and an if statement. Figure 2.7(b) is the stream graph. Because the program contains an if statement, the multiplicities of the kernels depend on the data. However, within each shaded region, R0, R1, and R2, the program is homogeneous Synchronous Dataflow (SDF).
The ASM sees the program after it has been partitioned. Imagine that the partition is as given in Figure 2.8(a), so that task D contains kernels f1, f2, and g1, and task E contains kernels h1, k1, and k2. The tasks execute at the same frequency, but they both contain kernels from inside and outside the if statement. Conditional execution of g1 and h1, including modelling of computation times and their pushes and pops, is driven using a control variable in the trace.
(a) SPM source program
Figure 2.7: Example stream program with data-dependent flow
Task Kernels D f1, f2, g1 E h1, k1, k2 (a) Partition
Figure 2.8: Representation of data-dependent flow between tasks and subtasks
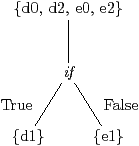
Figure 2.8(c) is one way for the compiler to implement the given partition. The tasks are decomposed into subtasks, d0, d1, and d2, and e0, e1, and e2. Figure 2.8(b) shows the control flow hierarchy that controls the execution. The subtasks at the root are always executed, d1 is executed if the control variable is True, and e1 is executed if it is False. Figure 2.6(d) shows an execution trace where the decision values for this node are False, True, ⋯. The control variable attached to a while node is similar, but it counts the number of iterations of the loop.
There are no explicit streams carrying the control variables of if or while statements between tasks. The compiler ensures that such tasks are consistent with each other, and may in the general case have to add such streams to do so. There are, however, examples where it would be unnecessary. It is assumed that the compiler produces correct code, and the ASM uses the control-flow hierarchy to ensure that its own model is consistent.
1 A stream is defined by the size of each element, and the location and length of either the separate producer and consumer buffers (distributed memory) or the single shared buffer (shared memory). These buffers do not have to be of the same length. If the producer or consumer task uses the peek primitive, then the buffer length should be reduced to model the effective size of the buffer, excluding the elements of history. The Finite Impulse Response (FIR) filters in the GNU radio benchmark of Section 2.5 are described in this way. It is possible to specify a number of elements to prequeue on the stream before execution begins.
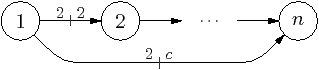
The platform is characterised using the small suite of synthetic benchmarks illustrated in Figure 2.9. All benchmarks have variable number of bytes transferred per iteration, denoted b. The producer-consumer benchmark is used to determine basic parameters, and has two actors: a producer, and consumer, with two buffers at each end. The chain benchmark, is a linear pipeline of n tasks, and is used to characterise bus contention. The chain2 benchmark is used to model latency and queue contention, and is a linear pipeline, similar to chain, but with an extra cut stream between the first and last tasks. The number of blocks in the consumer-side buffer on the cut stream is a parameter, c.
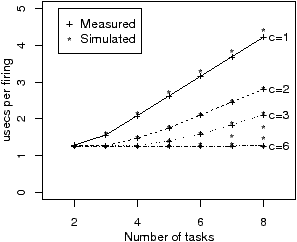
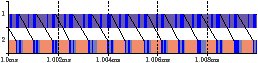
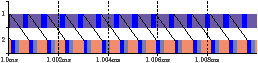
This section characterises the IBM QS20 blade, which was two Cell B.E.s (processors). Figure 2.10 shows the time per iteration for producer-consumer, as a function of b. The discontinuity at b=16KB is due to the overhead of programming two DMA transfers. For b<20.5KB, the bottleneck is the computation time of the producer task, as can be seen in Figure 2.12(a) and (b), which compares real and simulated traces for b=8K. For b>20.5K, the bottleneck is the interconnect, and the slope of the line is the reciprocal of the bandwidth: 25.6GB/s. Figure 2.12(c) and (d) compares real and simulated traces for b=24K. The maximum relative error for 0<b<32KB is 3.1%.
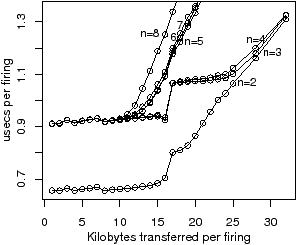
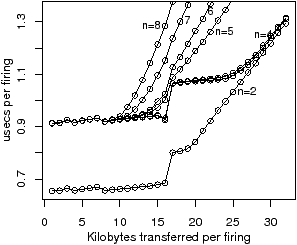
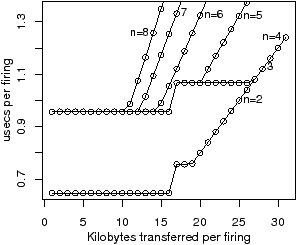
Figure 2.11 shows the time per iteration for chain, as a function of n, the number of tasks, and b, the block size. Figure 2.11(a) shows the measured performance on the IBM QS20 blade, when tasks are allocated to SPEs in increasing numerical order. The EIB (Element Interconnect Bus) on the Cell processor consists of two clockwise and two anticlockwise rings, each supporting up to three simultaneous transfers provided that they do not overlap. The drop in real, measured, performance from n=4 to n=5 and from n=7 to n=8 is due to contention on certain hops of the EIB, which the ASM does not attempt to model. As described in Section 2.2, the ASM models an interconnect as a set of parallel buses. Figure 2.11(b) shows the average of the measured performance of three random permutations of the SPEs. The simulated results in Figure 2.11(c) are hence close to the expected results, in a probabilistic sense, when the physical ordering of the SPEs is not known.
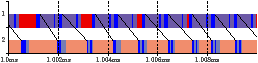
Figure 2.11(d) shows the time per iteration for chain2, as a function of the number of tasks, n, and the size of the consumer-side buffer of the shortcut stream between the first and last tasks, denoted c. The bottleneck is either the computation time of the first task (1.27us per iteration) or is due to the latency of the chain being exposed due to the finite length of the queue on the shortcut stream. Figure 2.12(e) and (f) shows real and simulated traces for the latter case, with n=7 and c=2.
This section describes the validation work using the ACOTES GNU radio benchmark, which is based on the FM stereo demodulator in GNU Radio [GNU]. Table 2.1(a) shows the computation time and multiplicity per kernel, the latter being the number of times it is executed per pair of l and r output elements. Four of the kernels, being FIR filters, peek backwards in the input stream, requiring history as indicated in the table. Other than this, all kernels are stateless.
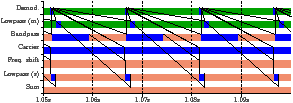
Figure 2.12: Comparison of real and simulated traces
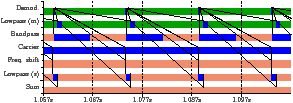
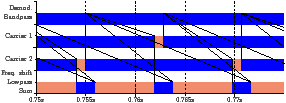
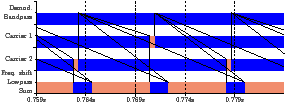
-1 Table 2.1 shows two mappings of the GNU radio benchmark onto the Cell B.E. The first allocates one task per kernel, using seven of the eight SPEs. Based on the resource utilisation, the Carrier kernel was split into two worker tasks and the remaining kernels were partitioned onto two other SPEs. This gives 79% utilisation of four processors, and approximately twice the throughput of the unoptimised mapping, at 7.71ms per iteration, rather than 14.73ms per iteration. The throughput and latency from the simulator are within 0.5% and 2% respectively.
Kernel Demodulation Lowpass (middle) Bandpass Carrier Frequency shift Lowpass (side) Sum (a) Kernels
Kernel 1 Demodulation 2 Lowpass (middle) 3 Bandpass 4 Carrier 5 Frequency shift 6 Lowpass (side) 7 Sum
Kernel 2*1 Demodulation Bandpass 2 Carrier (even) 3 Carrier (odd) 4*4 Lowpass (middle) Frequency shift Lowpass (side) Sum
Table 2.1: Kernels and mappings of the GNU radio benchmark
This section explains how the ACOTES stream compiler uses the ASM machine description and simulator.
The partitioning phase in Section 3.2 decides how to fuse kernels into tasks, and allocates these tasks to processors [CRA09a]. It represents the target as an undirected bipartite graph, H=(VH,EH), taken directly from the ASM. The weight of processor p, denoted wp is its clock rate in GHz, and the weight of interconnect u, denoted wu is its bandwidth in GB/s. The static routing table is determined using minimum distance routing, respecting the interfaceRouting parameters. We didn’t find it necessary to store the routing table explicitly in the ASM.
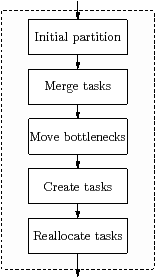
Figure 2.13(a) shows the main stages in the partitioning phase. An initial partition is constructed by recursively subdividing the target and program. The partition is then improved using several optimisation passes.
The partitioning phase uses connectivity sets [CRA09a] to constrain the mapping to make sure the compiler can support it. In particular, the ACOTES compiler can only fuse kernels that are lexicographically adjacent in the same basic block. Each connectivity set is therefore a pair of adjacent kernels in the same basic block. In a more advanced compiler, we would expect the connectivity sets to be as illustrated in Figure 2.7(b).
The queue length assignment phase in Section 3.3 allocates memory for stream buffers, subject to memory constraints, and taking account of variable computation times and task multiplicities [CRA10b]. The objectives are to maximise throughput and minimise latency.
This phase is an iterative algorithm, which uses the ASM simulator to find the throughput, utilisation, and latency, given the candidate buffer sizes. As mentioned in Section 1.3, simulation is used because a mathematical model is unlikely to capture the real behaviour.
Figure 2.13(b) shows the main stages in the queue length assignment phase. A cycle detection algorithm uses statistics from the ASM simulator to find the bottleneck. There are two cycle detection algorithms: the baseline algorithm uses only the total wait time on each primitive on each stream, and the token algorithm tracks dependencies through tasks. The buffer size update algorithm chooses the initial buffer sizes, and adjusts them to resolve the bottleneck. The evaluation algorithm monitors progress and decides when to stop, choosing the buffer sizes that achieved the best performance-latency tradeoff.
The inputs to the queue length assignment phase are the stream program, minimum buffer sizes, and the memory constraint graph. The minimum buffer sizes can be one block, because an SPM stream program is acyclic. The memory constraint graph is a bipartite graph, H = (RH, EH), where the vertices are the processors and memories, and the edges connect processors to their local memories. Figure 2.14 shows a memory constraint graph for the Cell B.E.
The memory constraint graph is generated from the addressSpace parameter for each processor. The remaining capacities are taken from the size parameters of the memories, minus the sizes of any code and data already in them.
Recent work on stream programming languages, most notably StreamIt [TKA02] and Synchronous Data Flow (SDF) [LM87], has demonstrated how a compiler may potentially match the performance of hand-tuned sequential or multi-threaded code [GR05].
Most work on machine description languages for retargetable compilers has focused on describing the ISA and micro-architecture of a single processor. Among others, the languages ISP, LISA, and ADL may be used for simulation, and CODEGEN, BEG, BURG, nML [FVPF95], EXPRESSION [HGG+99], Maril and GCC’s .md machine description are intended for code generation (see; e.g. [RDF98]). The ASM describes the behaviour of the system in terms of that of its parts, and is designed to co-exist with these lower-level models.
The Stream Virtual Machine (SVM) is an intermediate representation of a stream program, which forms a common language between a high-level and low-level compiler [LMT+04, MTHV04]. Each kernel is given a linear computation cost function, comprised of a fixed overhead and a cost per stream element consumed. There is no model of irregular dataflow. The SVM architecture model is specific to graphics processors (GPUs), and characterises the platform using a few parameters such as the bandwidth between local and global memory. The PCA Machine Model [Mat04], by the Morphware Forum, is an XML definition of a reconfigurable computing device, in terms of resources, which may be processors, DMA engines, memories and network links. The reconfigurable behaviour of a target is described using ingredients and morphs. Unlike the ASM, the PCA Machine Model describes the entire target, including low-level information about each processor’s functional units and number of registers.
-1 ORAS is a retargetable simulator for design-space exploration of stream-based dataflow architectures [Kie99]. The target is defined by the architecture instance, which defines the hardware as a graph of architecture elements, similar to the resources of the ASM. The purpose is performance analysis rather than compilation, and the system is specified to a greater level of detail than the ASM.
Gordon et al. present a compiler for the StreamIt language targeting the Raw Architecture Workstation, and applying similar transformations to those discussed in this chapter and the next [GTA06]. As the target is Raw, there is no general machine model similar to the ASM. The compiler uses simulated annealing to minimise the length, in cycles, of the critical path. Our approach has higher computational complexity in the compiler’s cost model, but provides retargetability and greater flexibility in the program model.
Gedae [LBS] is a proprietary stream-based graphical programming environment for signal processing applications in the defence industry. A version of Gedae has been released for the Cell processor. The developer specifies the mapping of the stream program onto the target, and the compiler generates the executable implementation. There is no compiler search algorithm or cost model.