This chapter describes the support tools that were developed in the course of this thesis. StarssCheck is a debugging tool, based on Valgrind [NS07], that finds bugs in StarSs programs. Paraver Animator (prvanim) is a simple tool that helps visualise the progress of a parallel application, by creating an animated GIF file. StreamIt to OmpSs (str2oss) is a tool to convert streaming programs in the StreamIt language into task based programs using StarSs.1.
A programming language without debug tools may be a fine research vehicle, but it is unlikely to be widely adopted, as users become frustrated by bugs in their code, blame the compiler, and think that the language is hard to use. Moreover, parallel programs often harbour subtle intermittent bugs, which may not be noticed for months or years. If StarSs or OmpSs become mainstream, and if they are used for production code, then people will want as much evidence as possible that their code is free of hidden bugs.
This section describes StarssCheck, a debugging tool that finds bugs in StarSs programs. It was used, for example, to check the output of the StreamIt to StarSs converter described in Section 5.3. Similar ideas could be used in a tool supporting SPM. The tool was written for StarSs because StarSs is more mature, and it already has real users.
Section 1.4.1 explains StarSs in enough detail to understand StarssCheck. It suggested that the pragmas could sometimes have been written by the compiler instead of the programmer. StarssCheck is the converse. Although it is hard for the machine to work out the pragmas from scratch, it is relatively easy for the machine to check them.
StarssCheck checks that tasks only access memory that they are supposed to. A task can read any argument marked as input, but it mustn’t change it. This could be enforced using const in C, assuming one never removes const using a cast. Adding const to existing code can be time-consuming, however, so is often avoided. A task can read or write any argument marked as output or inout, and modify the stack at or below its arguments. A task can always execute its code and read constant values. It mustn’t access any other data in memory2, something that is certainly hard for the compiler to check statically. If the task does try to read or write elsewhere in memory, it normally wouldn’t be stopped from doing so; the program might seem to work most of the time, but have intermittent bugs—see Section 5.1.1.
StarssCheck uses an analysis tool that runs under Valgrind [NS07], a widely-used framework for binary instrumentation. The default Valgrind tool, memcheck [SN05], warns the user whenever the program’s behaviour depends on invalid data; for example when a conditional branch depends on the contents of memory returned by malloc. StarssCheck is not specific to Valgrind. It requires a binary translation tool that has some mechanism similar to Valgrind’s client requests, which are calls from the guest program into the analysis tool. The tool could, for example, have been written for Pin [LCM+05].
As mentioned in Section 1.4.1, a compiler that doesn’t understand StarSs will ignore the pragmas, and compile a valid sequential program. StarssCheck runs the sequential version of the program under Valgrind, and checks that, for the supplied input, the pragma annotations are correct. StarssCheck can be adapted to any programming language for which a valid sequential program can be easily derived; e.g. by ignoring pragmas or keywords. It also requires the language to supply some restrictions on the regions of memory that can be accessed by a task; there is little point if a task can freely access shared memory.
Figure 5.1 illustrates the main errors that can be found using StarssCheck. In Figure 5.1(a), the function accesses memory via a pointer embedded in a structure. This pointer, unlike the function arguments, will not have been tracked or renamed by the OmpSs runtime system. The read will not be seen as a dependency between tasks, and, on distributed memory, the data will not have been transferred via DMA. On CellSs, p->ptr is a pointer in the PPE’s address space, but it is being dereferenced on an SPE.3 Normal load and store operations on an SPE are not subject to memory protection, and addresses wrap modulo the size of the local store, so the function will read some value. The PPE and SPEs all use 32-bit pointers, which are not distinguished by the C type system.
In Figure 5.1(b), the function reads outside array x. This example also shows how StarSs supports variable length arrays: by specifying the length in the pragma rather than the C prototype. The tool must therefore handle array sizes that are not known until run time. Conversely, in Figure 5.1(c), if isLong==0, the array is declared larger than necessary, and neighbouring memory will be corrupted if the caller has allocated an array smaller than 20 elements.
Subfigure (d) is missing a pragma wait before the main program accesses array x. A wait is required even for write-after-read dependencies, because task creation returns immediately without taking a copy. The original contents of the array should remain unmodified until all tasks that read it have been allocated to SPEs, and outgoing DMAs have completed. All missing waits are race conditions, hence non-deterministic and notoriously hard to debug.
In Figure 5.1(e), the direction of data transfer is incorrect. This bug will often be easy to find because it is so blatant, but it can also be found by StarssCheck. In Figure 5.1(f), the author has not noticed that argument x can be NULL. While StarSs could be extended to allow NULL variable pointers, and pass them unmodified to the task, this is not the current behaviour. This example, and the example in Figure 5.1(c) may cause exceptions deep inside the run-time library, for which source may not be available.
StarssCheck finds all the mistakes in Figure 5.1. It is also a good place to check whether function arguments are correctly aligned for CellSs. This constraint is imposed by the Cell B.E. DMA engine [IBM09, §7.2.1].
Figure 5.1: Example mistakes found by StarssCheck
Figure 5.2 shows the structure of StarssCheck. A translation tool reads the StarSs annotations from the source code, generating a wrapper function for each task. It also translates the finish and wait pragmas into appropriate macros. Translation currently uses a Python script, but a more robust tool, based on Mercurium [BDG+04], would be better. The translated source code is compiled as normal, and executed under Valgrind, using the Starssgrind tool.
An alternative is to take an executable generated by the OmpSs compiler, and intercept all calls to the run-time library. The benefit would be that the program would not need recompilation, but only if you are using the same variant of OmpSs; and not, for example, CellSs (since Valgrind does not support the Cell B.E.). This approach would work, but it also would be specific to a certain version of the run-time API, which may change in future.
StarssCheck uses Valgrind’s client request mechanism, which recognises a “magic” sequence of instructions in the binary. The instructions achieve nothing useful, unless the program is running under Valgrind, in which case they are recognised as a call into the analysis tool.
Table 5.1 lists the client request macros provided by Starssgrind. The precise semantics are given in Section 5.1.2, but the general idea is apparent in Figure 5.3, which shows the translated version of the bmod function (Figure 1.6).
Translation can be done using text substitution, without changing line numbers. Each task is given a wrapper function, which is a simple mechanism to define the region of stack it can touch, irrespective of the calling convention. The PUSH_CONTEXT macro enters a task. It sets up the task’s context, which initially allows access only to the .text section and the stack below the wrapper function’s frame pointer. The INPUT_BLOCK, OUTPUT_BLOCK and INOUT_BLOCK macros each declare a contiguous region of memory to be accessible by the task. The POP_CONTEXT macro leaves a task, and restores the master thread’s context. The master thread is subsequently allowed read-only access to the task’s input blocks, and no access to its output and inout blocks.
The WAIT_ALL and WAIT_ON macros support the finish and wait on pragma clauses, respectively. It is not necessary to translate the start pragma clause.
Figure 5.3: Translated version of the bmod function from Figure 1.6
Table 5.1: StarssCheck client requests
Request Description PUSH_CONTEXT(void) Enter task INPUT_BLOCK(void *address, size_t len) Declare input block OUTPUT_BLOCK(void *address, size_t len) Declare output block INOUT_BLOCK(void *address, size_t len) Declare inout block POP_CONTEXT(void) Return from task WAIT_ON(void *address) Restore given array WAIT_ALL(void) Restore all arrays
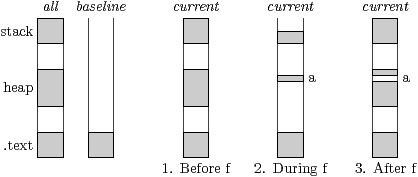
Starssgrind, the Valgrind tool, maintains several contexts, which define the accessible regions of memory. The current context is currently active: all accesses to memory are checked against it, and bad accesses immediately generate a warning. The all context defines the whole memory space accessible by the sequential program. It is the initial context for the main thread, and it defines the memory that the main thread can pass to tasks. The baseline context is the starting point for tasks, which contains only the .text section. Inside a task, the parent context defines the context of the main thread. When an array is passed to a task, it is removed or rendered read only in the parent context. Such regions are moved to the dead context, which records the sizes of arrays, so that when the main thread performs a wait, the correct region of memory can be restored.
A context is a disjoint set of regions, with each region covering a contiguous part of memory, with read-only or read-write access. The regions are stored in a balanced tree (our implementation uses a scapegoat tree [GR93]). Except within the dead context, adjacent regions with the same access rights get merged.
StarssCheck uses a tree representation rather than shadow bits for three main reasons. The first reason is that we do not expect the compiler to generate accesses outside the supplied arrays. This is different from validity checking in memcheck, where copying an array containing uninitialised padding should make the destination padding uninitialised, rather than immediately generating warnings. The second reason is that, for realistic programs, there are few active regions, so it is feasible to use a tree; often even a list is sufficient. The third reason is that extending memcheck’s efficient shadow bit representation to handle read-only regions and switching between contexts would be considerable work, with marginal benefit. See Section 5.1.3, however, for possible future work.
Figure 5.4: Starssgrind Contexts
Figure 5.4 shows the current context before, during, and after task f. Assuming f is the first task created, the context before calling f is the same as the all context. During f, only the stack below its arguments, the .text section, and the argument a are visible. After calling f, a is not accessible until the main thread waits on a.
Since it is expensive to traverse the context tree for every memory access, we use a direct mapped region cache, based on the instruction address. The access is first checked against the region that the instruction previously hit. The region cache is cleared after any client request that switches the current context or deletes memory from it. The cache check is inserted directly into the VEX IR, which is the static single-assignment intermediate code used by Valgrind. Figure 5.5 shows the intermediate code generated by a single store instruction, with the non-analysis code in bold.
1 t3:I32 t41:I32 t84:I32 t85:I1 t86:I32 t87:I32 t88:I1 2 3 ------ IMark(0x26A2, 4) ------ 4 |PUT(60) = 0x26A2:I32| 5 |t3 = GET:I32(4)| 6 |t41 = GET:I32(168)| 7 t84 = LDle:I32(0xF028E090:I32) 8 t85 = CmpLT32U(t3,t84) 9 DIRTY t85 ::: cs_helper[rp=3]{0xf0082850}(t3,0x1:I32,0x26A2:I32) 10 t86 = LDle:I32(0xF028E094:I32) 11 t87 = Add32(t3,0x4:I32) 12 t88 = CmpLT32U(t86,t87) 13 DIRTY t88 ::: cs_helper[rp=3]{0xf0082850}(t3,0x1:I32,0x26A2:I32) 14 |STle(t3) = t41|
Figure 5.5: VEX IR for a single store instruction: movss %xmm1,(%ecx). The address in the cache, for this particular instruction, is 0xF028E090
Most importantly, StarssCheck should find all the bugs within its remit, and it should not complain about code that is actually correct. In other words, it should have few false negatives (the former), and few false positives (the latter). StarssCheck finds all the mistakes in Figure 5.1, as confirmed by our test cases, and it only creates the false positives discussed in Section 5.1.3.
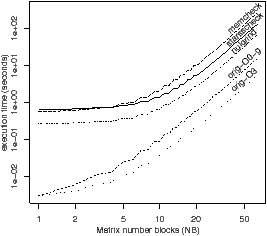
Figure 5.6: Performance results for Sparse LU factorisation
A tool such as StarssCheck will only be used if it is reasonably fast. Our experiments show that unless tasks are so small that OmpSs itself is slow, the execution time under StarssCheck is similar to memcheck, which should be acceptable.
Figure 5.6 shows the execution times for the sparse LU factorisation example from the OmpSs distribution, using the default block size of 32× 32. Figure 5.6(a) shows the execution time for square matrices up to 64× 64 blocks. For matrices of size about 640× 640 (20× 20 blocks) or above, the slowdown of StarssCheck is close to 8 times compared with the original, unoptimised code. For comparison, memcheck is about 16 times slower than the original, and nulgrind, which is Valgrind without instrumentation, is about four times slower.
Subfigure (b) compares four variants of StarssCheck, with the region cache enabled and disabled, and using either a tree or a linked list to hold the set of regions. The difference between the tree and linked list is insignificant for this example, but the cache gives a speed-up of about 3.5, if the matrix size is 16 blocks or more. The mean number of regions is approximately 9, requiring an average search depth of 1.5. The average number of regions decreases slightly as the matrix increases, because a greater proportion of time is spent in tasks, which have a below average number of valid regions.
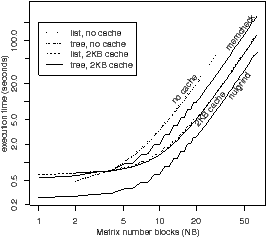
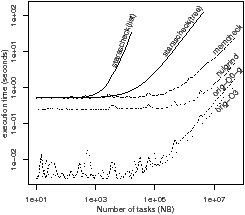
-1 Figure 5.7(a) shows the “nasty” benchmark, which is intended to show worst case performance. This benchmark has extremely fine grain tasks: each task contains a single arithmetic statement. StarssCheck has high overhead because OmpSs itself has high overhead. The execution times are shown in Figure 5.7(c) and (d), and StarssCheck is much slower than memcheck. The region cache provides little benefit, because every access to the a array misses. The average search depth in the tree increases logarithmically in the number of tasks, which is the worst case.
The problem with the “nasty” benchmark is that the tasks are too small. Unrolling is a standard technique to increase task granularity. Figure 5.7(b) is a better implementation of the program, with the loops both unrolled by a factor of 1,024. This requires the a array to be reordered. Figure 5.7(e) shows the execution time of the modified benchmark, which is comparable to memcheck.
1 ?#pragma css task inout(p)? 2 void f(int p[1024]) 3 { 4 int k; 5 for(k=0; k<1024; k++) 6 p[k] += 1; 7 } 8 9 int *nasty1k(void) 10 { 11 int *a = malloc(sizeof(int[NB*2048])); 12 int j,k; 13 memset(a, 0, sizeof(int[NB*2048])); 14 15 ?#pragma css start? 16 /* Process even blocks */ 17 for(j=0; j < NB*2048; j += 2048) 18 f(&a[j]); 19 20 /* Process odd blocks */ 21 for(j=1024; j < NB*2048; j += 2048) 22 for(k=0;k<1024;k++) 23 a[j+k] += 1; 24 ?#pragma css finish? 25 return a; 26 }(b) Source code (nasty1k)
(c) StarssCheck in context
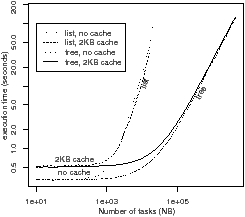
(d) StarssCheck variants
(e) After unrolling by 1,024
Figure 5.7: Worst case “nasty” benchmark
The main limitation of StarssCheck is that, unlike memcheck, it does not track the validity of data. Figure 5.8(a) shows a task with an output block that should be marked inout. There is in fact, inside StarssCheck, no difference between OUTPUT_BLOCK and INOUT_BLOCK, since both allow the task to read and write, and both make the block inaccessible to the main thread until it waits.
Fortunately, this error can be found using memcheck. It is advisable to run under memcheck in any case, because memcheck finds errors that are outside the scope of StarssCheck. StarssCheck could include a translator that invalidates memory corresponding to each output array, using the VALGRIND_MAKE_MEM_UNDEFINED memcheck client request. Clearly the functionality of memcheck and StarssCheck could be combined into a single tool.
The current implementation of StarssCheck fully supports CellSs, and a subset of SMPSs. SMPSs introduces array region specifiers, which describe a region in a multi-dimensional array, and opaque pointers, which are ignored by the run-time, and allow tasks to exploit the shared memory hardware. Array region specifiers require a straightforward extension to bounds checking. StarssCheck should skip validity checking for addresses calculated via opaque pointers. This requires tracking, either using static analysis or shadow bits similar to memcheck. Tracking of opaque pointers is orthogonal to the rest of the tool.
Figure 5.8(b) shows an example where StarssCheck can generate spurious warnings. A SIMD implementation of strlen may read memory above and below the string itself (but inside the same memory page). Note that memcheck also has difficulty following some C library functions [SN05], and we can use the existing Valgrind machinery to replace functions such as strlen. Section 5.3.1 describes how the StreamIt to OmpSs converter introduces memcpy operations between the inputs and/or outputs and temporary arrays; these suffer from a similar problem. It does not use Valgrind’s replacement machinery as yet; instead, it uses a simple version of memcpy when the code is to be executed under StarssCheck.
Also, certain C library functions, such as printf, do not respect the StarSs memory model. The suppressions mechanism of Valgrind can suppress any warnings that arise.
We are unaware of any other tools that check the input and output definitions of task-based programs. There are, however, several tools that find data races in shared memory. The crucial difference is that StarssCheck verifies information needed by the OmpSs run-time for the program to work at all, whereas the data race detectors discover unordered, and therefore racing, accesses to the same location in memory. Of the motivating examples in Figure 5.1, only subfigure (d) is a data race. The other errors cause the run-time to fail to transfer the correct data in or out of the task.
Figure 5.8: Potential false negatives and false positives
The Cilk Nondeterminator [FL99] finds data races in Cilk programs. A non-deterministic Cilk program is not necessary wrong, since the language provides locks and it allows communication through shared memory [MIT98]. Nondeterminator checks that programs that are supposed to be deterministic are in fact so. The algorithm assigns an ID to each task at runtime, and maintains, for every location in memory, the IDs of its most recent writer and some previous reader. It checks whether accesses are ordered via Cilk’s shared memory model. Its “SP-bags” algorithm assumes that dependencies between tasks follow a series-parallel DAG, which is true for Cilk but not for OmpSs. Hence it is unlikely to be possible to adapt the algorithm for our purposes.
Many tools find data races in multi-threaded programs. Helgrind [NS07] uses the Eraser algorithm [SBN+97] to find data races in POSIX pthreads programs. ThreadSanitizer [Ser09] uses a hybrid algorithm based on happens-before and locksets. CORD [Prv06] and ReEnact [PT03] are hardware techniques to detect data races. MTRAT [IBM] is a race detector for Java. Since a StarSs program is ultimately implemented using threads, these tools could find the data race in Figure 5.1(d), but they could not check whether the StarSs pragma annotations are correct.
This section describes the prvanim (Paraver Animator) performance tool, which was developed in the course of this thesis. It is a simple tool, which has, nonetheless, proven quite useful.
It accepts a Paraver trace, an index file, and various command-line arguments, and it generates an animated GIF, which shows the progress of the program through time. Each image in the GIF file shows the tasks completed or active at the end of its time interval, together with a simplified Paraver trace and optional legend at the bottom.
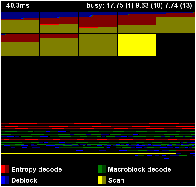
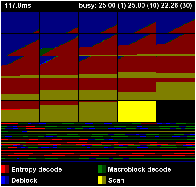
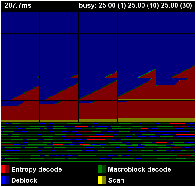
Figure 5.9 shows three images from an execution of the H.264 decoder on 25 processors. This is the scan variant of the H.264 decoder, which overlaps decoding of multiple output frames4. This example is for twenty five output frames, arranged in each image in row-major order; each pixel is a macroblock in one of the frames. The colours represent the four tasks that must be completed for each macroblock or frame, each of which is either currently working (bright) or completed (dark)—see subfigure (d). Almost all pixels in the images happen to be in one of four states: scanning for the next frame (whole frame is yellow), unprocessed macroblocks in a ready frame (dark yellow), entropy decoded macroblocks (red), or completed macroblocks (blue).
The index file maps task numbers in the Paraver trace to regions in the image. The tool paints the requested regions bright when the task starts and darker when it stops. The programmer has to somehow create the index file. Although this is extra work, it is an opportunity to write an index file that clearly represents the progress of the application, by laying out the image in whichever way makes the most sense. The str2oss tool has an option to generate a prvanim index file in addition to the C source code. Each row is a filter, and the iterations of the main loop are arranged from left to right; the width of each task is therefore inversely proportional to that filter’s multiplicity.
The prvanim tool is useful for understanding the big picture. Once the problem is understood in general terms, one may need to use Paraver to find the root cause—which may be a communications bottleneck, poor cache hit ratio, or some other problem.
This section describes str2oss (StreamIt to OmpSs), a tool to translate a streaming program written in StreamIt [TKA02] into a task based program using OmpSs. As mentioned in Section 1.4.1, the tool translated the StreamIt benchmarks to StarSs, which can be compiled using the OmpSs compiler, so that Chapters 3 and 4 could use the same benchmarks.
The tool converts the kernels in the StreamIt program into functions defining StarSs tasks. Each task processes one or more firings of its kernel’s work function. The tool also generates the main function. The main function allocates memory for the FIFOs, and it contains a loop, each iteration of which calls these functions as needed in a steady-state iteration.
The point of str2oss was to save time and enable the research in Chapter 4, rather than being a finished product. Nevertheless, it generates high quality code, so long as it is used with care. The major shortcoming of the tool is that it doesn’t support peeking forward in the stream, as indicated by peek N on a work function. It also doesn’t support feedback loops, variable rate kernels and teleport messaging. There are also some minor deviations from StreamIt syntax, driven by a pragmatic comparison of the cost of fixing str2oss and the cost of editing the benchmarks. Section 5.3.3 discusses these limitations of str2oss and suggests how they could be remedied.
The tool doesn’t do kernel fusion, as required by the partitioning optimisation from Section 3.2; and the queue sizing optimisation from Section 3.3 is irrelevant for OmpSs. It supports unrolling, under the user’s control, via a configuration file. It always generates code that works, but for good performance the user must control the high-level transformations described in Subsection 5.3.4.
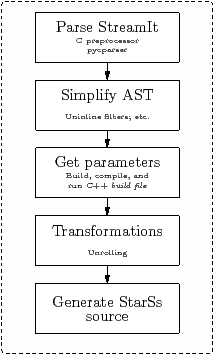
Figure 5.10 shows the steps in converting from StreamIt to StarSs. First, comments are removed using the C preprocessor5, and the StreamIt program is parsed, using a parser based on pycparser [Ben], to produce an AST (Abstract Syntax Tree).
The second step simplifies the AST. Its most important job is to deal with inlined filters, pipelines and splitjoins. These are written lexically inside their parent, and are most easily dealt with by moving them outside their parent, to the top level, and giving them a name such as Anonymous_5. The free variables are collected together to become parameters.
The third step builds the stream graph and finds out, for each filter, the values of its parameters and its static push, pop and peek rates. For the code in Figure 5.14, the parameters for the lowpass filters are rate, cutoff, taps and decimation. These values affect the push and pop rates, which are used to calculate the multiplicities, needed for static partitioning and scheduling. Knowing the values of all parameters ahead of time allows the main function to simply call the initialisation and work functions, without first having to follow the original hierarchical code to find out their parameters.
The tool constructs the stream graph and finds the parameter values by creating a C++ build program. The original StreamIt program is converted to C++, discarding the work and initialisation functions, keeping only the bits that build the stream graph, and calling C++ methods to do so. It prints to stdout a representation of the graph as shown in Figure 5.11. An alternative would be to analyse the code statically, but the approach described here was easier to implement.
In the output from the build program, the first field is whether the component is a filter, pipeline, or splitjoin. Since it is a linear representation of a hierarchy, each pipeline and splitjoin needs lines to open and close it, represented by the opening and closing square brackets. The second and third fields are the types of the data on the input and output FIFOs. These are usually already known because they are given in the source code, but not always—some inlined stream actors have their types deduced from the context, and this is done by the build program.
If the component is a filter, the next three fields give the number of elements popped, pushed, and peeked for each call to the work function. In StreamIt terminology, the peek count includes the number popped—since the tool doesn’t support peeking forward, the pop and peek counts should be equal. The depth field is included only to help debugging, as it gives a visual representation of the depth in the hierarchy. The remaining fields are the function name and the values of its parameters.
After reading in the output from the build program, the next step is to perform the high-level transformations described in Section 5.3.4. Following this, the final phase calculates the filter multiplicities, and generates the StarSs source code as described in the next section.
Type Input Output Pop Push Peek Depth Name and parameters
Figure 5.11: Output from the build program
Figure 5.12 shows how a StreamIt work function may be converted to a StarSs task. The actual code generated depends on the context in which the filter is being used. The code on the right is for a simple case, and is the unmodified output from str2oss. Since the filter’s push and pop rates are known by the caller, in fact at compile time, the items to be popped and pushed are passed, as function arguments in and out, in arrays of known sizes. The push, pop, and peek6 operations inside the function are translated to array accesses and pointer arithmetic.
(a) StreamIt filter (b) Corresponding StarSs function
Figure 5.12: Translation of an example StreamIt function
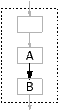
The main program uses arrays to hold the elements in the FIFOs. Figure 5.13 shows parts of the stream graphs for three StreamIt programs, with each subfigure indicating in bold a single array. Subfigure (a) is the simplest case: a FIFO straight from one filter, A, to another filter, B. The main program will allocate a block of memory large enough to contain all the data passed in a steady state iteration, and call functions similar to the function in Figure 5.12(b), one or more times per iteration, to write and read the array. A efficient serial implementation would share one array among several streams, if their data weren’t live at the same time, but this is not done by str2oss.
There is a complication, which is caused by a limitation of the OmpSs runtime. OmpSs doesn’t support dependencies via input and output arrays that partially overlap. A task’s input array must coincide exactly with the output array of the task that generated the data, and it must be disjoint with every other output—similarly for other kinds of dependency. This is a reasonable limitation, because the runtime finds the dependency using an associative map from the block’s start address to an internal data structure. Any more complicated mechanism would likely require greater runtime overhead.
The number of items pushed by the producer task may be different from the number popped by the consumer task. When they are different, a natural implementation would have them communicating via partially overlapping arrays, which would not work.
The approach taken by str2oss is to split the FIFO into segments of length the greatest common divisor of the push and pop rates. Rather than having a single output argument, out, to contain all the elements it will push, the producer gets one output argument per segment; similarly for the consumer. The data is manipulated in temporary arrays and gathered from or scattered to the arguments using memcpy. This approach sometimes results in an excessive number of function arguments, often solved with a careful choice of unrolling factor for one or both filters. This is the unrolling transformation described in Section 5.3.4. Although unrolling solves the problem on this stream, it may cause problems elsewhere, particularly if the unrolled filter is connected on the other side to a splitjoin. This behaviour is rather unintelligent, but it is easy to understand, and easy for the high-level phase to model.
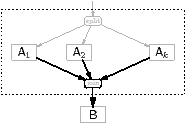
Figure 5.13(b) shows a FIFO that is the output of a round-robin join. The str2oss tool does not create a task just to do the job of the joiner. In some cases, this would be the right thing to do—see below, but, again, it is a high-level transformation. The elements in the array are ordered, in memory, exactly in the order they will be popped by B. The main program calls kernels A1 through Ak, having them write their contributions directly into this array. If a single firing of any of the producers has to write output that is not one contiguous section, then its output argument must be split into several arguments. The function arguments may need to be split further to deal with the limitation of OmpSs that was handled above. Conversely, the input to a splitjoin is handled in a similar way: it is an array with multiple readers instead of multiple writers. Figure 5.13(c) is an example where a stream leaves one splitjoin and enters another, so the array has multiple writers and multiple readers.
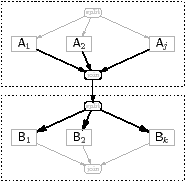
More complicated examples are handled by inserting an identity kernel, which does nothing except pass on data. For instance, if A1 in Figure 5.13(c) were not a kernel, but a splitjoin, an identity kernel would be inserted after its join. The reason is that it is genuinely harder to support nested splitjoins in the manner described above. In a single splitjoin, described in the previous paragraph, each filter writes a subset of the elements of its output array following a simple pattern: first skip so many elements; then for the rest of the array, alternate between writing a fixed number of elements and skipping a fixed number of elements. A filter inside a nested splitjoin, if not isolated from the outer one, could have to follow a more complicated pattern.
This section illustrates the conversion process using the example from Figure 1.10, a simplified version of part of the StreamIt fm benchmark. Since str2oss doesn’t support peeking forward in streams, the program has to be changed to work without peeking. This can often be done in the way shown in Figure 5.14, by adding state that remembers previous input: a history buffer. This program is not quite the same as the original, because there are 127 new samples, all zeroes, at the beginning of the output. There is also a performance overhead due to shifting samples in the history buffer, but this overhead can be reduced using a more careful unrolled implementation.
Figures 5.15 and 5.16 show the output from str2oss. The program as it stands is not very efficient, since the tasks are too small. They would normally be unrolled using the mechanism in Section 5.3.4.
The state on lines 16 and 17 of the StreamIt source code is combined into the structure defined on lines 7 through 11, and initialised by the init function on lines 13 through 27. The low pass filter is defined in lines 29 through 41. The subtracter, defined in lines 43 through 53, has its input arrays split in two, since it follows a two-way round robin join.
Figure 5.14: Non-peek version of the example StreamIt 2.1 program in Figure 1.10
Figure 5.15: Translated code exactly as generated by str2oss: part 1
Figure 5.16: Translated code exactly as generated by str2oss: part 2
The initial implementation of str2oss does not support peeking, feedback loops, variable rate kernels, or teleport messaging. To support peeking, the tool must allocate additional buffering, since stream elements are live for a longer time. It must also modify task creation order and add a prologue before the main loop, since peeking forward in the stream modifies the schedule.
There are three ways to implement the additional buffering. The first way is to implement a history buffer inside the task, which requires inout state. This transformation was done manually in Section 5.3.2, and it serialises the filter. The second way is to split the filter in two: the first half updates the history, and is therefore serialised. The appropriate data is passed to the second half of the filter, which does the work, and need not be serialised (unless there is some other inout state). The third way is to allocate and manage the additional buffering in the main function, and pass the appropriate data to the tasks using additional function arguments.
The prologue and main loop can be created using a technique such as phased scheduling [KTA03], which takes account of peeking forward in the streams.
Feedback loops present no special problems. Since feedback loops were not used in the StreamIt benchmarks, there was no requirement to implement support for them.
Variable rate kernels are hard to support without changing the StarSs programming model. In StarSs, the dependency graph must be constructed by the main function, which requires knowing the number of elements pushed or popped by every kernel’s work function. When a kernel has variable rates, the main function must therefore synchronise on every one of its tasks. This will likely introduce an unacceptably large overhead and constrain parallelism.
Teleport messaging allows occasional messages to be sent between filters, outside the normal stream flow. Messages are asynchronous method calls from an upstream (sending) filter to a downstream (receiving) filter, which have guaranteed upper and lower bounds on latency. Latency is measured, not using some notion of global time, but by reference to a pull schedule [CAG06].
Teleport messaging constrains dynamic scheduling [TKS+05]. If an upstream filter might send a message with fixed latency; i.e. the upper and lower bounds are equal, then each downstream filter task cannot start executing until the upstream task that may have sent it a message has finished executing. These dependencies must always be added to the dependency graph, even in the common case where there is no message.7 To add these dependencies, the downstream task must be created after the upstream task, which might not otherwise have been the case, especially if the minimum latency is large.
In addition to the major shortcomings described above, the tool requires some small changes to the StreamIt source code. Some of these relate to differences between StreamIt’s Java-derived syntax and that of C. Specifically, str2oss requires a semicolon after a typedef, and it requires the keyword struct before a struct name. Numbers beginning with a zero are treated as octal, whereas the mpeg2 benchmark for instance expects them to be decimal. These limitations can be addressed by modifying the parser.
Unlike StreamIt, variables are not automatically initialised to zero. There is no support for nesting ordinary C functions inside components; the programmer just needs to move them outside, adding arguments as necessary. The tool generates work functions with arguments with names like in, out, and state. These can be, and sometimes are, the same as local variables, causing problems.
The tool has incomplete support for StreamIt array declarations: the StreamIt declaration int[N] permutation is similar to the C declaration int permutation[N]. For this reason, the parameters to filters must be scalars. Two benchmarks have arrays passed as parameters: Serpent and fm. The workaround for Serpent is to change the second parameter from an array to a Boolean, which selects between IP and FP in the static data. The workaround for fm is even simpler: the work function depends on just one element of the gains array. This limitation can be addressed by supporting StreamIt array declarations properly.
The str2oss tool has limited support for the unrolling transformation, but only under the direct control of the user or external tool. The unrolling transformation is driven using a control file, such as that shown in Figure 5.17. Each line in this file is a directive to str2oss, which has a directive type, unrolling factor, and a regular expression. The regular expression matches the task function or task function call.
An UNROLL directive unrolls a task function. For example, the first line in Figure 5.17 unrolls the PolarToRectangular function by a factor of 2 000. This is done by inserting a for loop around the body of its work function, and multiplying the push and pop rates by this number. The filter unrolling pass happens after parsing the StreamIt code, but before creating and running the build program. Line 3 unrolls every function not matched by the first two lines by a factor of 100.
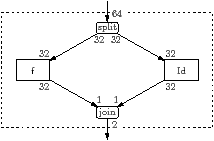
The JOIN and SPLIT directives fix the problem illustrated in Figure 5.18. Figure 5.18(a) shows part of the source code for the des benchmark, slightly simplified. As can be seen in the diagram of Figure 5.18(b), the outputs of f and Id are interleaved by a round-robin join. The code generation method described in Section 5.3.1 requires f to write the even elements into the array in the right places, and Id to similarly write the odd elements. For StarSs, since each argument must be a single block of contiguous memory, this requires the functions to both have, for their outputs, 32 function arguments.8
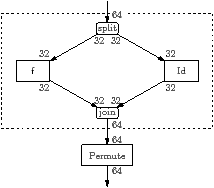
The solution is to transform the source code into that shown in Figure 5.18(c), resulting in the stream graph in Figure 5.18(d). The round-robin join has been changed from (1,1) to (32,32), and a permute filter has been inserted to put the stream back into the right order. A single call to f writes one block of contiguous memory, so the function has a single output array, and similarly for Id. This transformation is performed by the directive “JOIN 32 Body_1”. The SPLIT directive works similarly for splits. The regular expression is matched against the specific instance of the splitjoin, hence the suffix _1.
Figure 5.2 gives statistics for conversion of the StreamIt benchmarks. Subfigure (a) shows the statistics for the benchmarks, as used in Chapter 4, with manually chosen high level transformations. The only benchmark with an excessive number of function arguments is MPEGdecoder. This benchmark contains a round-robin split with arguments 384, 16, and 3. After the high-level transformations, the producer pushes 40 300 elements at a time into the split, which has arguments 38 400, 1 600, and 300. This FIFO must be split into segments, as described in Section 5.3.1, to avoid partially overlapping arrays. The current implementation requires all segments to be the same length. The segment is the greatest common divisor, which is 100, so the producer has 403 output segments. There is one additional function argument, which is a parameter to the filter. The solution is to fix this one benchmark by hand.
Figure 5.2(b) shows the same statistics when all filters are unrolled by a factor of 100. Some functions have an absurd number of function arguments, up to 45 thousand, for the reasons explained earlier in this section. For comparison, Figure 5.2(c) gives the same statistics for the StreamIt benchmarks with no high-level transformations at all.
Kernel fusion is not supported, but it could be implemented by modifying the graph representation and work functions immediately following unrolling. The transformation should be driven by a convex partition, determined, as above, either by the user or by an external tool, perhaps using the heuristic in Section 3.2. The transformation should contract the kernels to be fused into a single vertex. Any internal streams will disappear from the stream graph, but will become temporary buffering inside the task. The multiplicity of the task should be the greatest common divisor of the multiplicities of its kernels.
Figure 5.18: An example where str2oss generates a function with too many arguments
Benchmark BeamFormer1 BitonicSort ChannelVocoder DCT DES FFT FilterBank FMRadio MPEGdecoder Serpent tde VocoderTopLevel (a) As used in Chapter 4, with manually chosen transformations
Benchmark BeamFormer1 BitonicSort2 ChannelVocoder7 DCT2 DES2 FFT5 FilterBank6 FMRadio5 MPEGdecoder Serpent tde VocoderTopLevel (b) Unrolled only, all filters by factor of 100
Benchmark BeamFormer1 BitonicSort2 ChannelVocoder7 DCT2 DES2 FFT5 FilterBank6 FMRadio5 MPEGdecoder Serpent tde VocoderTopLevel (c) Not unrolled
Table 5.2: Translation statistics for StreamIt benchmarks