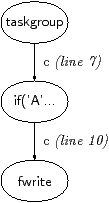All major semiconductor companies are now shipping multi-cores. Phones, PCs, laptops, and mobile internet devices already contain multiple processors instead of just one, and will require software that uses an increasing number of them effectively. Writing high-performance parallel software is difficult, time-consuming and error prone, increasing both development time and cost. Software outlives hardware; it typically takes longer to develop new software than hardware, and legacy software tends to survive for a long time, during which the number of cores per system will increase. Development and maintenance productivity will be improved if parallelism and technical details are managed by the machine, so that the programmer can concentrate on the application as a whole.
This thesis develops techniques to automatically map a certain class of program, known as stream programs, to multiple processors. Stream programs are significant subcomponents of many important applications, including those involving audio and video encoding and decoding, software radio, and 3D graphics. Moreover, due to their modularity and regularity, they ought to work well on multiple processors. In addition to investigating how to automatically map stream programs to multi-processors, this thesis introduces some tools that can be used to find bugs and improve performance.
Putting multiple CPUs into the same system is by no means new. The Burroughs D825 was the first Symmetric Multiprocessor; it had four processors, and it was launched in 1962 [AHSW62]. What is new, however, is that mainstream computing is currently being forced into multiprocessing. There are, in general, three ways through which computers become faster. First, transistors have been getting faster and smaller at an exponential rate, so last year’s design, on today’s semiconductor process, will be faster.1 Second, smaller transistors give more room for complicated mechanisms to speed up a single processor, either through increasing the clock rate by overlapping instructions in a pipeline, or through superscalar issue, by doing several unrelated instructions at once [HP07]. Both these techniques are limited, however, by excessive power consumption [OH05]. Third, an effective way to use an increasing number of transistors is to have on the same chip, several processors.
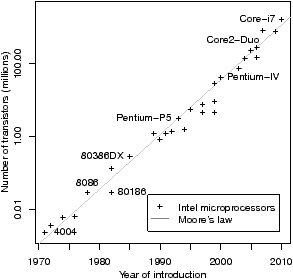
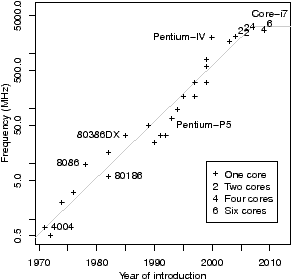
Figure 1.1 illustrates these trends, using data for Intel processors. Figure 1.1(a) shows that the total number of transistors has been doubling roughly every two years, consistently for about forty years, and that the trend is continuing still. Figure 1.1 (b) shows that clock frequency has been doubling roughly every three years, but that the trend has flattened in recent years, with transistors instead being used for multiple processor cores. Multiprocessing has been common in embedded systems and standard in supercomputing for many years, the former for power consumption and specialisation2 and to isolate subsystems from each other, and the latter because it is the only way to get the necessary performance. All supercomputers in the biannual TOP500 ranking [TOP] have had two or more processors ever since 1997, and the average number of processor cores in the machines in the November 2010 list is about 13,000.3
Multiple processors are pointless if they are not all kept busy, ignoring the benefits from specialisation for now; and they need to run, in parallel, on their own relatively large pieces of work. It is hard to write programs that do this. The first reason is that many computations, like many human activities, cannot easily be broken up into parts that can be done at the same time. An example is shown later in this section, in Figure 1.8(a). One way to find parallelism in such a program is to use a different algorithm. Another way is to use speculation to exploit the parallelism that exists but is hard to describe.
+1 The second reason is that, with some exceptions, breaking a single program into parts and managing their execution in parallel currently has to be done by the programmer. Moreover, doing so exposes some unpleasant technicalities [Lee06]: primarily, the need to lock data structures so two threads don’t try to change the same data at the same time and mess it up, and weak memory consistency, where interactions between processors reveal that they are not the sequential machines they pretend to be [AG02]. The programmer must manage all this, while also presumably thinking about the big picture, in terms of what the application is ultimately trying to do. Interactions between multiple processors are inherently non-deterministic, because the program’s behaviour can depend on the precise timing. Many bugs will therefore happen intermittently, and be difficult to reproduce, diagnose, and fix.
The parallelism that exists in software often has some kind of structure. A parallel programming model is a way for the application programmer to reveal this structure to the machine. The machine should then assign work to processors and deal with technicalities, allowing the programmer to concentrate on whatever the program is trying to achieve, which is probably also rather challenging. The main benefits are a shorter development time and lower cost, similar to the advantages of higher-level languages such as C or Python, compared with assembly language.
This thesis uses the three types of parallelism described in the following subsections.
Data parallelism [HS86] exists when the same operation has to be done, independently and many times over, on a large amount of data. Examples are doubling every entry in a large table of numbers and finding the sum of a list of values. The latter is an example of a reduction, the bulk of which is data parallel, if the sum is broken into parts using associativity of addition. Data parallelism can be found in linear algebra, manipulating vectors and matrices, and many scientific applications, including modelling physics and predicting the weather.
Data parallel operations can be distributed across multiple processors quite easily, conceptually at least, as illustrated in Figure 1.2. Crucially, the allocation of work to processors is done by the machine, rather than the programmer. At the small scale, data parallelism can also be exploited within a single instruction, using SIMD instructions,4 such as those in Intel MMX and SSE, IBM/Motorola AltiVec, and ARM NEON.
Data parallel programs can be written in languages such as OpenMP [Org08] and High-Performance Fortran (HPF) [HPFF93, HPFF97]. OpenCL [Khr10] and CUDA [NVI08] support data parallelism on GPUs. Google’s MapReduce [DG08] is a form of data parallelism at the large scale.
An alternative is to have the machine look for data parallelism in an ordinary sequential program. If a sequence of similar operations, in a loop, and supposedly to be done in order, do not depend on each other, then they can be done in parallel, and the result will be the same. The earliest work on data dependence analysis dates back to the 1970s [Lam74, KM+72, Mur71], and a considerable amount of research has been done since then [AK02].
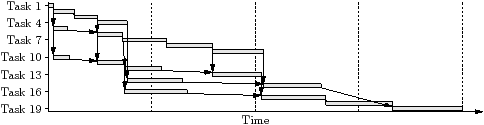
Another way to write parallel programs, known as task-level parallelism, is to have one thread, running on one processor, delegate self-contained pieces of work, known as tasks, to a pool of interchangeable workers. The workers are normally threads running on different processors. This is easy for people to understand because it resembles concurrency in the real world, and it can be very efficient. Figure 1.3 illustrates task-level parallelism using a Gantt chart.
One of the earliest task-level programming languages is Cilk [BJK+95]. In a Cilk program, any thread may spawn children, which potentially run in parallel with their parent. If a parent needs some value computed by one of its children, then it should first wait for its children to complete. There can be no dependencies between children; i.e. one child cannot wait for another child to finish, but parallelism can be nested, meaning that children can have children of their own.
In this thesis, task parallelism will be defined using StarSs [SP09, BPBL06, PBL08], which will be described briefly in Section 1.4.1. StarSs supports dependencies between tasks: one task may be dependent on the outputs from other tasks, its predecessors, meaning that it cannot start until they have finished.
Table 1.1 lists some other languages and libraries for task parallelism, including OpenMP 3.0 [Ope09], TPL (Task Parallel Library) [LSB09] for .NET, Apple’s Grand Central Dispatch [App] in Mac OS X 10.6, and Intel Threading Building Blocks [Rei]. Task parallel programming is also used for specific applications; for example dense linear algebra in the PLASMA [Uni09] and FLAME [FLA10] projects. MPI Microtask [OIS+06] for the Cell B.E. breaks a message-passing program into non-blocking units of computation, which are dynamically scheduled as tasks.
Language Year † Nesting Dependencies Cilk [BJK+95] 1995 Yes Parent can wait for children pthreads [iee99] 1995 Yes Shared data and locks High Performance Fortran (HPF) 2.0 [HPFF97] 1997 Yes Yes Jade [RSL02] 2002 Yes General DAG1 StarSs [SP09, BPBL06, PBL08] 2004 ‡ Yes General DAG Sequoia [FHK+06] 2006 Yes Parent waits for children Intel Threading Building Blocks [Rei] 2007 Yes General in Version 3 Update 5 OpenMP 3.0 [Ope09] 2008 Yes Parent can wait for children Task Parallel Library (TPL) [LSB09] 2009 Yes General DAG using futures StarPU [ATNW09, ATN10] 2009 No General DAG using tags OpenCL 1.1[Khr10] 2010 No General DAG OoOJava [JED10] 2010 Yes General DAG from static analysis Tagged Procedure Calls (TPC)[TKA+10] 2010 No Master can wait for tasks Apple Grand Central Dispatch [App] 2010 Yes Tasks can wait for other tasks Intel Cilk Plus [Int10] 2010 Yes Parent can wait for children † Date of first significant publication
‡ GridSs
Table 1.1: Selection of task parallel languages and libraries
Language Year † Graph structure Dimensions Gedae [LBS] 1987 General directed graph One-dimensional Gabriel [BGH+90] 1990 General directed graph One-dimensional Ptolemy II [EJL+03] 2003 General directed graph One-dimensional StreamIt [TKA02, CAG06] 2001 Series-parallel One-dimensional StreamC/KernelC [Mat02] 2002 General directed graph One-dimensional DataCutter [BKSS02] 2002 General directed graph One-dimensional Brook [Buc03] 2003 General directed graph Multi-dimensional S-Net [GSS06] 2006 Series-parallel One-dimensional SPM [CRM+07, ACO08] 2007 General DAG One-dimensional Fractal [MRC+07] 2007 General directed graph Multi-dimensional XStream [GMN+08] 2008 General DAG One-dimensional GRAMPS [SFB+09] 2009 General directed graph One-dimensional IBM InfoSphere SPL [IBM11] 2009 General directed graph One-dimensional DUP [GGR+10] 2010 General directed graph One-dimensional † Date of first significant publication
Table 1.2: Selection of stream programming languages
Another, more specialised, way to write parallel programs is known as streaming parallelism. Unlike data and task parallelism, which are applicable to many different types of problem, streaming parallelism is domain-specific. Domain-specific languages (DSLs) have long been used to improve productivity. They let the program be described at a higher level, although they lack the generality of a general purpose language such as C. For example, Matlab is for scientific computing, and YACC is for writing parsers of context-free grammars. Other examples include BPEL, Make, Excel, SQL, and DiSTil [SB97, VDKV00].
There has recently been considerable interest in the use of domain-specific languages for parallelism. The high-level description reveals implicit parallelism, which would be obscured by a sequential language such as C [DYDS+10, CSB+11]. Examples of domain-specific languages that expose implicit parallelism include Make, OpenGL [Khr] and SQL [CHM95].
Stream programming is suitable for applications that deal with long sequences of data; these sequences are known as streams. Streams arise naturally in time-domain digital signal processing, where the streams are discrete-time signals, and 3D graphics, where the streams are long sequences of vertices and triangles. The objective is usually to maximise throughput, or to reduce power or energy consumption for a given throughput. These applications can usually tolerate a large latency compared with the rate at which data arrives.
It is either impossible or impractical to store the entire streams, so computation is done online, on local subsets of the data. Computation is done inside kernels, which communicate in one direction, from producer to consumer, through the streams. In digital signal processing, many of the kernels are digital filters. This representation exposes modularity and regularity to the compiler, enabling the compiler transformations discussed below. It is easy to understand stream programming because it is also like concurrency in the real world: a new gadget is being produced at the factory, while older ones are in the hands of the consumers.
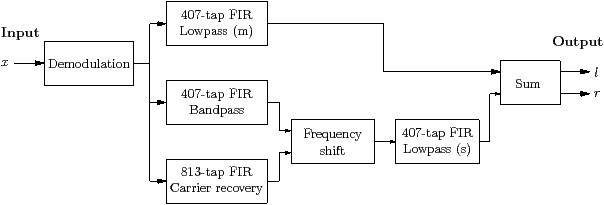
Streaming programs can be represented graphically, as in Figure 1.4. This is a picture of an FM stereo demodulation example,5 which is based on GNU radio [GNU]. Each box represents a kernel, and each edge is a stream that carries data from its producer to its consumer. The seven kernels interact in no other way, so they could be working at the same time, on seven different processors.
Digital-signal processing and 3D graphics are examples of one-dimensional streaming, meaning that the streams are inherently one-dimensional. The kernels are therefore either stateless, in which case each stream element is processed independently from the others, or stateful, in which case dependencies between elements mean that the kernel must be done sequentially. Video encode and decode are examples of multi-dimensional stream programming. Some of the kernels iterate over a two- or three-dimensional space, and contain data parallelism that can only be exploited using wavefronts.
The reason to write an application as a stream program is that a machine can do a good job of mapping a stream program to the hardware. First, it often happens that some kernels involve much less work than others, and it makes sense to combine several small kernels into one. The programmer can safely write many small kernels, knowing that when there are few processors, small kernels will be merged, and the performance will be as good as if the programmer had done it. Deciding which kernels to fuse together is known as partitioning, and is addressed in Section 3.2. Second, unlike task-level programming, there is no master thread that can become the bottleneck. Third, the compiler can choose to batch work up into larger chunks, benefiting from lower overheads, and economy of scale through data reuse and vectorisation. This process is known as unrolling. Larger pieces of work have disadvantages too: they require more working memory, so might not fit in cache, and they cause data to take longer to go through the stream program, causing a longer latency.
Fourth, it often happens that some kernels themselves contain data parallelism, so can be divided up to run on several processors in parallel. An example is a volume control, which multiplies each audio sample by some slowly changing value that represents the volume. Since each sample has no influence on any other, there is no state, and the work could be shared among several processors. The FM demodulation example in Figure 1.4 contains several Finite Impulse Response (FIR) filters, which are also stateless.
Streaming parallelism can be reduced to task-level parallelism, by breaking each kernel up into a sequence of tasks. It is usually not possible, however, to go the other way: it is hard for a compiler to deduce kernels and streams from the program source, and then use the optimisation techniques mentioned above.
The programmer’s job is to write the source code, the human readable instructions to the computer. The computer translates the source code to machine readable object code, a process known as compilation, and will usually perform optimisations at the same time. Optimisations at compile time are effective because redundant or unnecessary work is removed for good, regular operations can be collected to run in parallel using SIMD instructions (vectorisation [LA00]), and program fragments can be customised for a particular context using constant folding [Muc97], polyhedral optimisations [CGT04] and so on. Moreover, analysis costs are paid just once. A second opportunity for optimisation is at install time, when the executable can be tweaked for the specific machine it is going to run on. This thesis will not distinguish between compile time and install time, and will assume that the compiler knows precisely what the target machine will be. The machine is described to the compiler using the ASM (Abstract Streaming Machine), defined in Chapter 2.
The final opportunity for optimisations is at run time, while the program is actually running. This is when the most information is available, when the program’s behaviour can be observed, and the environment is known: whether other programs need the CPUs, the power source, battery level and CPU temperatures, and so on. Optimisation at run time is effective because it can take account of this extra information, but CPU time is spent doing run-time analysis rather than real work, and program fragments cannot be customised at compile time.
In brief, predictable parts of the stream program will be statically partitioned and scheduled; i.e. the decisions will be made at compile-time. Chapter 3 addresses the compile-time decisions. The poorly balanced and unpredictable parts of the stream program will be broken up into tasks to be handled as task-level parallelism, and scheduled dynamically, at run time. This is especially important for video applications, including H.264. Chapter 4 addresses dynamic scheduling of stream programs.
This work was partly supported by the ACOTES project [ACO, M+11],6 which defined a stream compiler framework, and developed a demonstration stream compiler. The ACOTES compiler framework partitions a stream program to use task-level parallelism, batches up communications through blocking, and statically allocates communications buffers. The stream program is written using the Stream Programming Model (SPM) [CRM+07, ACO08, M+11], an extension to the C programming language, developed for the ACOTES project and described in Section 1.5.2.
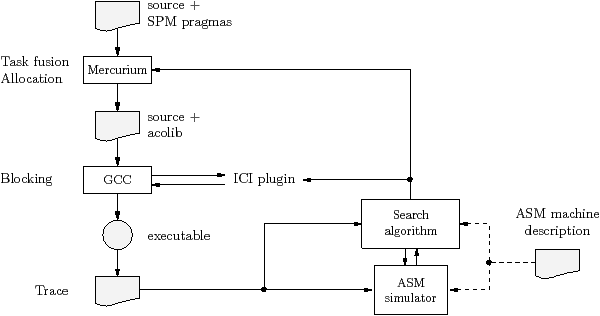
Figure 1.5 shows the compilation flow. The source program is converted from SPM to C, using the Mercurium [BDG+04] source-to-source converter. This step translates pragma annotations into calls to the acolib (ACOTES library) run-time system, and inserts calls to the trace collection functions. It fuses kernels that are mapped to the same processor, encapsulating them into routines, and inserts statically sized communication buffers, as required, between kernels on different processors. The mapping is determined by the partitioning algorithm described in Chapter 3. The resulting multi-threaded program is compiled using GCC, which was extended within the ACOTES project to perform blocking, polyhedral transformations, and vectorisation. Additional mapping information is provided to GCC using the Iterative Compilation Interface (ICI) [FC07]. The ACOTES compiler is iterative, meaning that the program may be compiled several times, as the search algorithm adjusts the mapping.
The ASM simulator executes a mapped stream program at a coarse granularity, and generates statistics which are used to improve the mapping. The inputs to the simulator are the ASM machine description, which describes the target, and the ASM program model, which describes the program. The ASM simulator is driven by a trace, which allows it to follow conditions and model varying computation times.
The ASM simulator is used inside the small feedback loop in the bottom right of Figure 1.5; for example in determining the size of the stream buffers, using the algorithm in Section 3.3 [CRA10b]. The trace format has been designed to allow a single trace to be reused for several different mappings. Section 2.6 describes in more detail the partitioning algorithm and its interaction with the ASM.
The ASM simulator allowed work to start on the mapping heuristics before the compiler transformation infrastructure was completed. Additionally, and experiments are repeatable because there is no experimental error.
Figure 1.6: Example StarSs code (bmod function from LU factorisation)
Task-level parallelism will be expressed, in this thesis, using Star Superscalar (StarSs), an extension of the C programming language, developed at BSC–CNS.7 The extensions are “pragmas” that tell the compiler about tasks, but they don’t change what the program does. If a StarSs program is given to an ordinary compiler, that does not support StarSs, it will ignore the pragmas, and the program will still work—just not in parallel.
StarSs is an umbrella term for the common parts of GRID Superscalar [SP09], Cell Superscalar (CellSs) [BPBL06], and SMP Superscalar (SMPSs) [PBL08], plus generalisations for GPUs (Graphics Processing Units) and clusters. CellSs targets the Cell Broadband Engine [CRDI05], which has distributed memories, and needs the run-time system to program DMA transfers to get data from one processor to another. SMPSs targets Symmetric Multiprocessors, which have a global shared address space, so DMA transfers are not required. For more information please refer to the conference publications cited above and the CellSs [Bar09] and SMPSs [Bar08] manuals.
OmpSs is an implementation of StarSs, which also integrates the OpenMP standard. The OmpSs compiler accepts both the StarSs syntax and the newer OmpSs syntax [DFA+09].
Figure 1.6 shows a short function, the bmod function from LU factorisation, annotated with its StarSs pragma. This function works on subblocks of larger arrays: the subblocks called row and col are inputs, and therefore not modified by the function, and the subblock called inner is read and modified (inout). Pragmas contain some extra information, beyond the direction of data transfer. First, a pragma says that the function should be a task in the first place; i.e. that it is big enough, and worth offloading to another processor, given the overheads of a software run-time.8 Second, when the formal parameter is a pointer rather than an array, the pragma gives the array’s size (an example is given in Figure 5.12(b) on page ??). This information is needed, but otherwise not given by the C source.
Figure 1.7: Extracts from StarSs code for Cholesky decomposition
The program starts executing on one processor, in the master thread. When the master thread calls a function like bmod marked as a task, the function does not execute right away. Instead, a task, to do that function, is added to a run-time dependency graph, to be executed some time in the future in a worker thread.
The dependency graph tracks dependencies between tasks, since some of the inputs to bmod may not be ready yet. They may be outputs from tasks that haven’t yet been done. Not all task-level languages allow tasks to depend on earlier tasks, instead needing the main thread to wait for the predecessors to complete before it can fire off any task that needs their outputs. Supporting dependencies is an important feature of StarSs, and it is easy to imagine that it might improve performance.
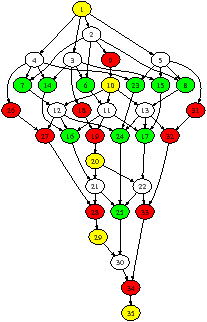
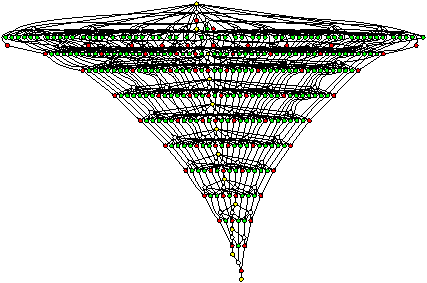
Figure 1.7 shows the function prototypes and part of the compute function from the Cholesky decomposition benchmark. Figure 1.8 shows dependency graphs for two different problem sizes.9 The different colours correspond to the four functions, and the numbers in subfigure (a) show the order in which the tasks were created. In practice, the whole dependency graph may never exist in this complete form, because tasks appear only after they have been created, and are removed once they have been done.
Since several versions of one particular array may be in flight at once, the OmpSs run-time renames arrays to break false dependencies, in a similar way to register renaming in a superscalar processor.10 Even if task B modifies an array that is going to be needed by task A, task B can be offloaded and even start executing before task A has finished. Task A will always read the version it was supposed to, even if that version has since been superseded by a new one. If the main thread needs the output of some task, it must request the data using a pragma. The pragma waits for the task to complete and ensures that the live data is copied back.
The compiler could potentially have looked through the function in Figure 1.6, and written the pragma itself, without a person having to do it. This function is rather easy to analyse statically, but other functions are harder.11 Alternatively, it could watch the function, while the program is running, and see that it never seems to modify row, for example, guessing that the annotation should be input(row). This approach needs a lot of test cases to ensure that no special cases are overlooked. StarSs could therefore be used as a form of intermediate language, to separate machine analysis from the run-time system.
In any case, we are interested here in using the OmpSs runtime to implement dynamic scheduling for a streaming language, by splitting kernels into tasks. So the pragmas are going to be generated by the machine anyway.
StreamIt [TKA02, CAG06] is a programming language for streaming applications, developed at MIT. All computation is performed by filters, connected together by FIFOs, with decentralised control rather than a master thread. Each FIFO carries data from a single producer filter to a single consumer filter. Data arrives at the consumer in the order sent; that is first-in first-out.
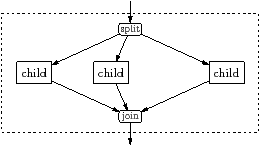
The stream graph is built hierarchically, using pipelines, splitjoins, and feedback loops. These components12 are illustrated in Figure 1.9. All components, including filters, have a single input FIFO and a single output FIFO.
A pipeline connects its children in sequence, so the output of each child component is the input to the next—see Figure 1.9(a). A splitjoin connects its children in parallel, as shown in Figure 1.9(b). The input FIFO is split among its children, either by duplication, or by distributing its elements in a weighted round robin fashion. The output FIFOs are always joined using weighted round robin. Splits and joins are the only vertices in the stream graph that can have more than one predecessor or successor; but they only distribute or gather data, rather than being free to do arbitrary work.
A feedback loop introduces a feedback path from the output of its body child back to its input, as shown in Figure 1.9(c). The feedback path optionally contains a component, referred to as the loop. It may need one or more elements prequeued onto the output of the loop component so that it does not deadlock.
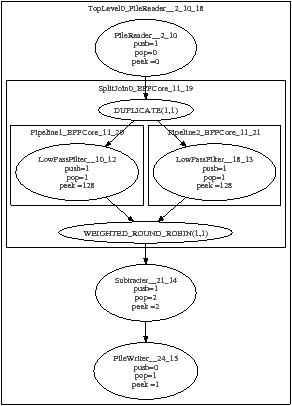
Figure 1.10 shows an example StreamIt program, which is a bandpass filter, implemented as the difference of two lowpass filters.13 The stream graph is deduced at compile time, and is shown in Figure 1.11. The top level of the program is the pipeline defined in lines 54 to 65. It contains four children, inserted using the add statements, which in turn read the input, calculate the two lowpass filters, subtract elements in pairs to get the difference, and write the output.
Figure 1.10: Example StreamIt 2.1 program, based on FMRadio5
The two lowpass filters are contained in the splitjoin called BPFCore, defined in lines 40 to 45. The splitter duplicates each element on the input FIFO to go to both filters, the filters happen on its two branches, and the joiner interleaves their outputs.
The lowpass filter is defined in lines 15 to 38. It is of type float→float, meaning that its input FIFO holds elements of type float, and so does its output FIFO. Line 16 declares its local data: a coefficient array whose number of elements is equal to taps. This array is built by the initialisation function in lines 17 to 28.
Every filter has a work function that keeps getting called, until the program has finished. In this case the work function is defined in lines 29 to 38. Each time this work function is called; i.e. each time it fires, it pops a fixed number of elements from its input FIFO and pushes a fixed number of elements into its output FIFO. The StreamIt 2.1 language supports work functions that push or pop a variable number of elements; in which case, the programmer may specify the minimum, maximum, and average number of elements. All StreamIt benchmarks, however, currently have fixed rates.
Here, the number of elements popped is equal to 1 + decimation. The exact number must be determinable at compile time. Since the filters are added in lines 42 and 43, both times with decimation equalling zero, both filters pop one element each time they fire. This is known in Figure 1.11, which was produced by the StreamIt compiler. Similarly, they both push one output element each time they fire, and they look ahead, or peek 128 elements in the stream, counting from the starting point. That is, they need 127 elements in addition to the one they will pop.
Each filter is stateless, meaning that the calls to their work functions are independent, so the filter contains data parallelism. A stateful filter has dependencies from one firing of the work function to the next, because its work function writes to local data. For example, it could be an adaptive filter that modifies its coefficient array, coeff. The compiler would see that the work function modifies local data, and make sure that it is done sequentially.
This example illustrates the features of StreamIt that are important in this thesis. For more information about StreamIt, refer to the language definition [CAG06], which is only twenty pages in length. The example does not illustrate static blocks, which contain read-only data visible to all filters. It also does not illustrate some of the more advanced features unused by the StreamIt benchmarks, and not supported by our conversion tool: feedback loops, described above, messaging, which is a mechanism for asynchronous messaging between tasks, prework functions, which replace the work function the first time a kernel fires, or support for variable push and pop rates.
This dissertation uses the StreamIt 2.1 language definition [CAG06], and the compiler and benchmarks from the StreamIt 2.1.1 distribution, dated January 2007.
Figure 1.12: Example SPM program from [M+11]
The SPM [CRM+07, ACO08, M+11] (Stream Programming Model) is an extension to the C programming language to support stream programming, developed in the ACOTES project. Whereas StreamIt is a new language that requires the program to be restructured to look like a streaming program, SPM uses pragmas to annotate an ordinary C program. The pragmas identify parts of the program to be made into kernels. Like StarSs, if an SPM program is given to an ordinary C compiler, which doesn’t support SPM, it will ignore the pragmas, and the program will still work. That is, SPM maintains the sequential semantics of C.
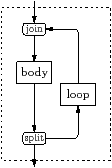
Figure 1.12 shows an example program using the SPM, and its stream graph. The streaming part of a program is known as a taskgroup, and it comprises the loop following the acotes taskgroup pragma, here on lines 5 to 13. This taskgroup has two tasks, each of which contains the statement or block following an acotes task pragma. The task’s inputs and outputs are identified using the input and output clauses.
The SPM program begins running in a single thread. When execution reaches the taskgroup, all of its tasks are created, each becoming a kernel in the language of this thesis, and the program starts processing data in streams, passing inputs and outputs through the streams. More information can be found in the ACOTES documentation [CRM+07].
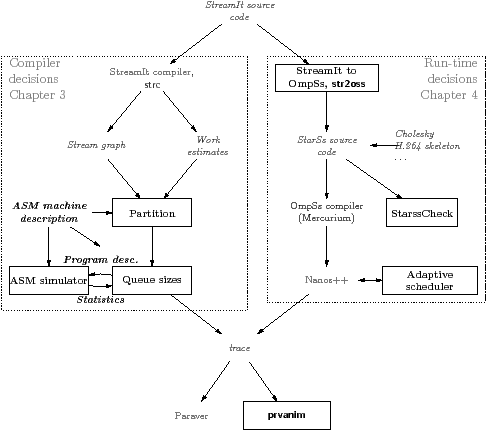
Figure 1.13 shows the tool flow used in this thesis, with the contributions of the thesis shown in bold. The left-hand side of the diagram is for the compile-time decisions in Chapter 3, and the right-hand side is for the run-time decisions in Chapter 4.
On the left, the StreamIt source code is compiled using the StreamIt compiler, which, in addition to creating an executable, also creates a file representing the stream graph, in dot format [GKN06], and a text file giving its estimate, for each filter, of the amount of work per firing. These files are the input, together with the ASM machine description, to the partitioning algorithm in Section 3.2. After partitioning, the buffer sizes are determined using the buffer sizing algorithm in Section 3.3.
The right-hand side of the diagram is for the run-time decisions in Chapter 4. The StreamIt source code is first translated to StarSs, using the tool described in Section 5.3. The StarSs source code is built using the Mercurium OmpSs compiler.
The various dynamic scheduling techniques, including the two proposed adaptive techniques, were compared using a set of OmpSs benchmarks built in this way.
When people start using a new programming language and compiler, they will soon discover that some of their programs don’t work. They will need to find out why, before they can fix them. A programming language without debug tools may be a fine research vehicle, but it is unlikely to be widely adopted, as users become frustrated by bugs in their code, blame the compiler, and think that the language is hard to use.
Section 5.1 describes a debugging tool, StarssCheck [CRA10a], that was developed as part of this thesis. It finds bugs in StarSs programs, but similar ideas could be used in a tool supporting SPM. StarssCheck was used, for example, to check the output of the StreamIt to OmpSs converter described in Section 5.3. The reasons for targeting StarSs rather than the SPM are that StarSs is more mature, and it already has real users.
In this thesis, the main reason to bother to write and compile an application to run in parallel is to improve its performance. When the performance is disappointing, or in some way surprising, it is important to understand why, and this requires some way to see how the application progresses.
The main tools used for this purpose in this thesis were Paraver [CEP] and prvanim (Paraver Animator). Paraver is a trace visualisation tool, developed at BSC–CNS. Paraver reads a trace in a straightforward format [CEP01], which is a text file that can be easily created either using custom code or the Mintaka library [Nanb].
Section 5.2 describes the prvanim tool, which was developed in the course of this thesis. It takes a Paraver trace, and produces an animation that shows the progress of the application through time. It is a simple tool, which has, nonetheless, proven quite useful.
In order to use the same StreamIt benchmarks throughout the thesis, these benchmarks had to be translated to StarSs, so they could be compiled by the OmpSs compiler. For that purpose, we developed str2oss, a source-to-source compiler that translates from StreamIt to StarSs. This tool is described in Section 5.3. It does not support kernel fusion, but it does support unrolling, using a control file given by the user.
Each filter is translated into a work function, and, if required, an initialisation function. The work function does the work required by one firing of the filter, and is marked as a StarSs task. The tool creates a main thread, which allocates memory for the streams, and implements the steady state by calling the tasks in sequence.
The main contributions and publications of this thesis are:
The Abstract Streaming Machine (ASM), a machine model and coarse-grain simulator for a statically scheduled stream compiler.
A new partitioning heuristic for stream programs, which balances the load across the target, including processors and communication links. It considers its effect on downstream passes, and it models the compiler’s ability to fuse kernels.
Two new low-complexity adaptive dynamic scheduling algorithms for stream-like programs.
StarssCheck, a debugging tool for StarSs. This tool checks memory accesses performed by tasks and the main thread, and warns if the StarSs pragmas are incorrect.
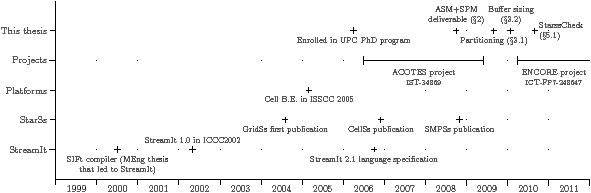
Figure 1.15 shows a timeline, which places the contributions of this thesis in context. It also shows the two European projects that supported this work. The ACOTES project, which ran from mid-2006 to mid-2009, partially supported the ASM and compile-time heuristics. The ENCORE project, which started in March 2010, partially supported the run-time work, which includes StarssCheck and str2oss. The timeline also shows some external milestones, related to the Cell B.E., StarSs and StreamIt.
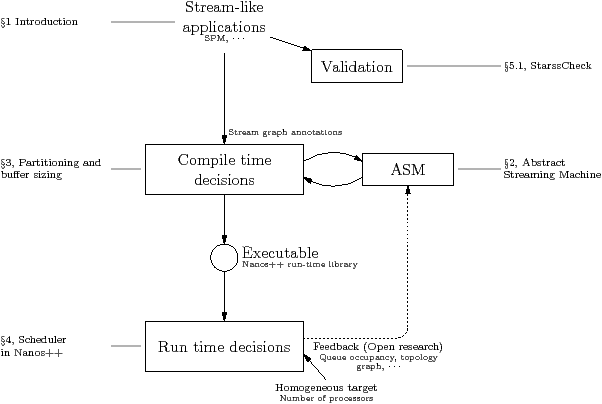
Figure 1.14 shows the structure of the rest of this thesis. Chapter 2 describes the ASM, the Abstract Streaming Machine, that characterises the machine on which the stream program is going to run. The ASM tells the compiler how many processors there are, and how they are connected. Chapter 3 concerns the decisions made at compile time: the partitioning algorithm, and an algorithm that decides how big the communications buffers should be. The output from the compiler is an executable using the Nanos++ library [Nana]. This library includes an implementation of the OMP Superscalar runtime. Chapter 4 deals with run-time scheduling of stream programs.